 微信扫一扫
微信扫一扫Fish Audio:AI文本转语音和声音克隆工具
Fish Audio官网 在数字化时代,音频内容的创作和分发变得越来越重要。Fish Audio作为一个创新的AI驱动平台,提供了强大的文本转语音(TTS)和声音克隆解决方案,正在改变我们创建和管理音频内...
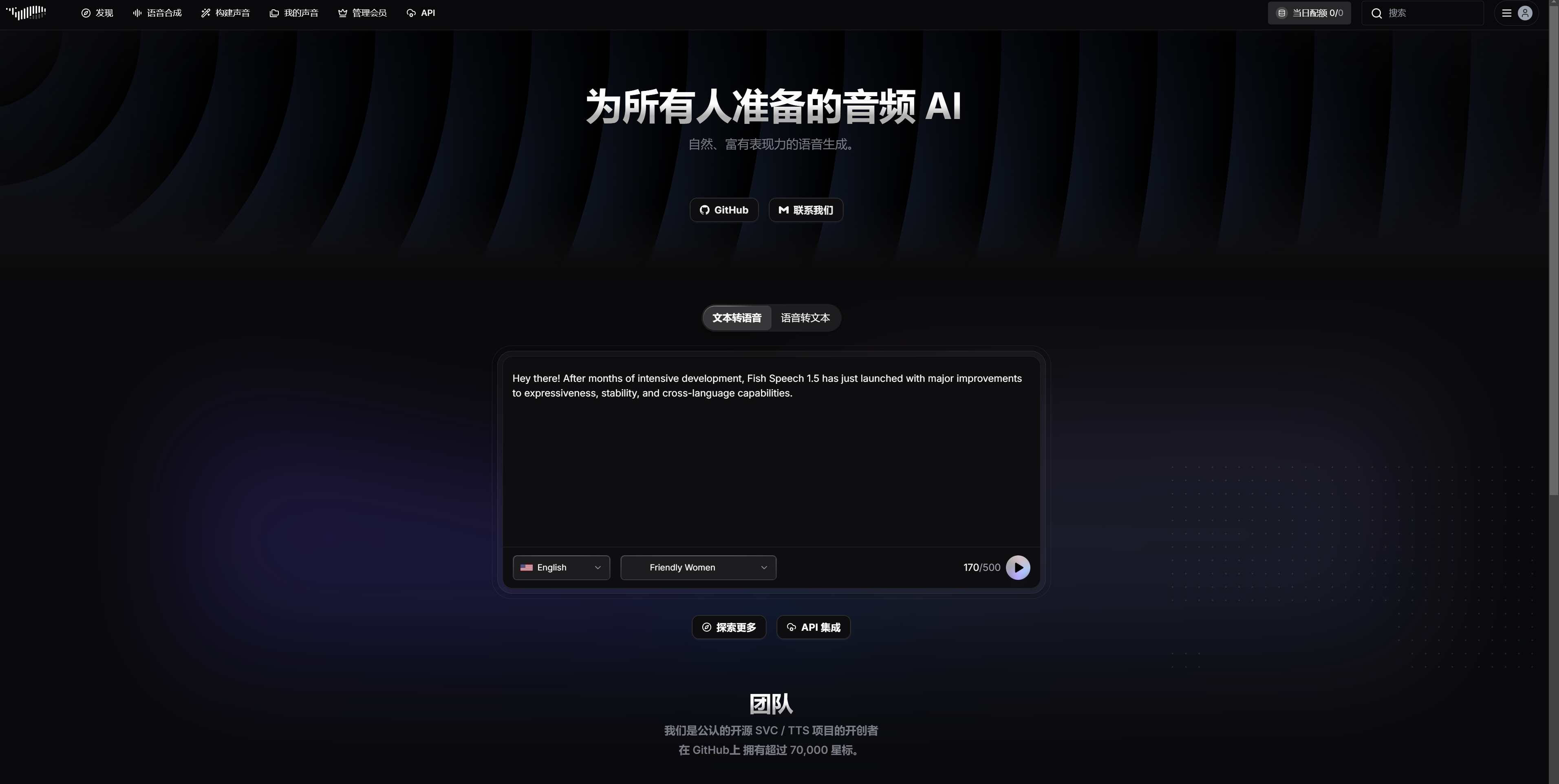
在数字化时代,音频内容的创作和分发变得越来越重要。Fish Audio作为一个创新的AI驱动平台,提供了强大的文本转语音(TTS)和声音克隆解决方案,正在改变我们创建和管理音频内容的方式。
Fish Audio简介
Fish Audio是一个专注于文本转语音(TTS)技术的平台,致力于开发高质量的语音合成模型。该平台发布的Fish Speech模型基于VQ-GAN、Llama和VITS等前沿AI技术,能够将文本转换成逼真的语音。支持中文、日语、英语三种主流语言,Fish Audio的合成音质堪比专业配音,适用于教育、商业演示、辅助阅读、游戏配音等多种场景。
功能特点
Fish Audio的操作简便快捷,用户只需输入文本并选择语音,即可一键生成所需的语音文件。其完全开源的语音模型允许任何人免费使用和改进代码。此外,Fish Audio提供多种自然流畅的语音声音选项,用户可以根据需要选择不同的声音模型,生成更加自然流畅的语音。
技术原理
Fish Speech的技术基础建立在多个先进的机器学习和深度学习概念之上,包括大规模预训练、Transformer架构、多任务学习、声码器技术和多语言嵌入技术。这些技术的应用使得Fish Speech能够处理和生成高质量的语音,语言处理能力接近人类水平,并且声音表现形式丰富多变。
应用场景
Fish Audio的多功能性使其在多个领域都有广泛的应用。无论是有声读物和音频书籍的制作、辅助技术、语言学习、客户服务还是新闻和播报,Fish Audio都能提供高效的语音合成服务。
Fish Audio以其高质量的语音合成服务和易用性,为用户提供了一个强大的语音解决方案。无论是个人创作者还是企业用户,都能通过FishAudio提升产品的语音交互体验,实现高效的信息传递。通过Fish Audio,音频内容创作变得更加便捷和高效,开启了音频创作的新纪元。