 微信扫一扫
微信扫一扫强化学习揭秘:如何通过自我学习提升AI智能和效率
说到AI,大家第一反应是什么?大部分人可能会想到“人工智能可以做很多事情,像人一样聪明”。可你有没有想过,AI是如何变得越来越聪明的?是因为它自己“学会了”? 对,AI不仅仅是按照预设的程...
说到AI,大家第一反应是什么?大部分人可能会想到“人工智能可以做很多事情,像人一样聪明”。可你有没有想过,AI是如何变得越来越聪明的?是因为它自己“学会了”?
对,AI不仅仅是按照预设的程序在运行,它其实是在通过自我学习变得更强。这背后的核心技术之一,就是强化学习。但这听起来是不是有点高深,仿佛只有学过人工智能的人才能理解?其实并不是,你不必是专家,也能通过一些类比和例子,理解这个改变AI命运的“秘密武器”。
如果把传统学习比作学校的课堂学习,那强化学习就是给AI提供一个“实践”的机会,让它通过做错和改正,不断进步。就像你学习骑自行车一样,摔倒了再站起来,最后学会平衡。只不过AI的摔倒是“错的决策”,而“站起来”则是根据反馈调整它的策略。
那么,强化学习是如何帮助AI进行自我优化的呢?接下来,我们一探究竟。
什么是强化学习?我们到底让AI学了些什么?
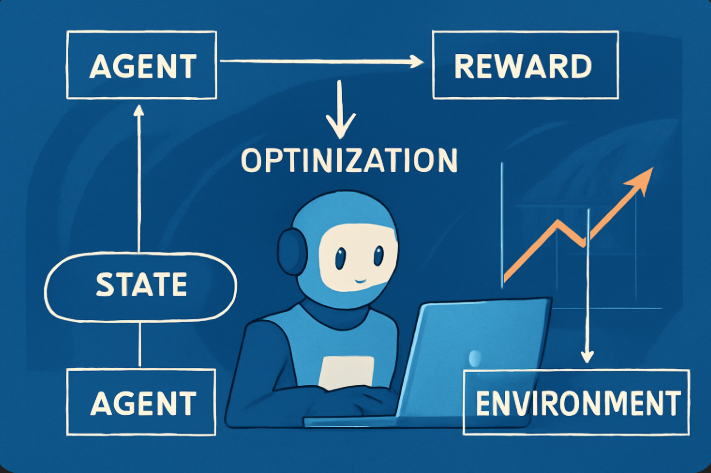
强化学习(Reinforcement Learning, RL)其实是一种学习方法,它模仿了自然界中动物如何通过“试错”来学习。具体来说,AI通过不断地在一个环境中“尝试”不同的行为,然后根据环境给它的反馈(奖励或惩罚)来优化它的决策。
就像你训练宠物狗一样,狗狗做对了一件事,你奖励它一点零食;做错了,可能就不给它零食。经过反复的训练,它会学会做正确的事,去获得奖励。强化学习中的AI也是这样,它通过不断“试探”,得到反馈,然后调整自己的行为来获得更多的“奖励”。
1. 强化学习的基本组成部分
- Agent(智能体):可以理解为“学习者”,就是AI的本体。
- Environment(环境):AI所处的外部世界,包括它的所有行为和反馈。
- Action(行为):AI在环境中采取的操作,比如在围棋中下一步棋。
- Reward(奖励):AI在某次行为后获得的反馈,通常是一个数值。AI的目标是最大化奖励。
- Policy(策略):AI如何选择行为的规则。也就是说,它根据当前的状态决定下一步做什么。
- Value Function(价值函数):AI用来评估状态好坏的标准,帮助它判断哪些行动值得执行。
为什么强化学习能帮助AI变得更智能?
想象一下,如果你一直告诉AI该做什么,结果它就永远只能按照你告诉它的去做,哪怕有更好的做法。那么它的“智慧”就只停留在你赋予它的范围内了。强化学习的出现,突破了这种局限性,允许AI在实际操作中通过反馈来改进自己的决策策略。
2. 强化学习如何提升AI性能?
强化学习的核心思想就是通过奖励反馈来引导AI进行决策优化。你可以把它想象成一个“智能化的反馈循环”,这个循环不断优化AI的决策,从而使它的表现越来越好。
- 探索与利用:AI的学习本质上是“探索”和“利用”的平衡。探索是指AI尝试新的行为,可能会出错;利用是指它利用已经获得的经验做出最佳决策。这两者需要平衡,过度探索会浪费时间,过度利用则会导致“固守旧思维”。
- 延迟奖励问题:强化学习中的奖励往往是延迟的,可能不是马上就能获得反馈。例如,你给AI一个任务,它可能需要执行几次操作后,才会看到最终效果。这就要求AI不仅要关注当下的反馈,还要推测出下一步的行动是否会带来更好的长远回报。
通过这些机制,AI可以在真实环境中自我优化、迭代,从而变得更加高效和精准。
强化学习的应用场景:从围棋到自动驾驶
那么,强化学习到底在哪些实际场景中发挥着作用呢?让我给你几个生动的例子:
3.1 围棋:AlphaGo的突破
2016年,Google DeepMind的AlphaGo战胜了世界围棋冠军李世石,震惊了全球。而其背后核心技术之一就是强化学习。
- 如何做的:AlphaGo通过自我对弈学习,不断“试探”不同的棋步,然后通过奖励反馈来优化自己的决策。它通过这一过程,掌握了数以百万计的围棋技巧,最终超越了人类围棋大师。
这不仅是AI的一项突破,也是强化学习如何“自我进化”的经典例子。它通过不断尝试、优化,最终达到人类无法企及的水平。
3.2 自动驾驶:让车“学会”如何开车
自动驾驶是强化学习的另一个应用领域。自动驾驶车辆需要在复杂的交通环境中做出决策,比如判断什么时候加速、什么时候刹车、如何避开行人。
- 如何做的:通过强化学习,自动驾驶系统能够在模拟环境中不断测试自己的驾驶策略,经过数百万次的反馈调整,逐步优化自己的驾驶决策,最终在实际道路上实现安全驾驶。
强化学习帮助自动驾驶系统从零开始,学会如何处理复杂的交通场景,避免交通事故,提高驾驶的安全性。
3.3 游戏AI:通过游戏提升策略
AI在游戏中的应用也在不断扩展,尤其是策略类游戏,比如《星际争霸》或《Dota2》。AI通过强化学习,能够从零开始,并且通过与其他玩家对战来提高自己的游戏策略。
- 如何做的:AI通过强化学习,模拟不同的游戏场景和策略,然后根据胜利与失败的反馈不断调整游戏行为。随着时间推移,AI在这些复杂的游戏中展现出了惊人的“智慧”,甚至能够打败一些顶级人类玩家。
强化学习面临的挑战与未来
虽然强化学习在很多领域取得了巨大进展,但它也面临一些挑战。
4.1 持续性与稳定性
强化学习依赖大量的训练数据和时间,这意味着AI的学习过程可能非常缓慢。在一些复杂的环境中,AI可能需要数以万计的训练回合才能取得理想的效果。
4.2 资源消耗
强化学习在训练过程中需要大量的计算资源,尤其是在一些大型模拟或复杂任务中。随着任务复杂度的增加,计算成本也大幅上涨,这限制了其广泛应用。
4.3 适应性与泛化能力
尽管AI通过强化学习学会了某些任务,但它的适应性和泛化能力仍然有限。换句话说,当它遇到一些未曾训练过的新场景时,可能会表现得不尽如人意。
AI自我学习的未来:开启智能时代的新篇章
尽管目前的强化学习系统还存在一些瓶颈,但随着计算能力的提升和算法的不断优化,AI的自我学习和优化能力将变得更强。它将不再仅仅是执行任务的工具,而是能够自主适应、优化和创造的“智能体”。
强化学习的未来不仅仅在于它如何让AI变得更聪明,更在于它如何重新定义人类与机器的关系。从更加智能的自动驾驶,到更强的医疗诊断系统,再到能够自主作曲的AI艺术家,强化学习将推动AI进入新的“自我进化”阶段,开启属于智能时代的新篇章。